2026/02/19


株式会社S-fleage 代表取締役CEO
京都大学大学院 MBA|同志社大学大学院 博士課程在籍
サイバーエージェントでデジタルマーケティング戦略支援に携わった後、2016年に創業。デジタルマーケティング領域は10年以上のキャリア。
同じ質問を、ChatGPT、Claude、Gemini、Grokの4つのLLMに投げてみました。
お題は「従業員50名のIT企業が、エンジニア採用で大手に負け続けている。半年以内に改善する採用ブランディング施策を提案してください」というもの。予算500万円、知名度の低さがボトルネック——という条件も揃えています。
返ってきた4つの回答は、どれも「採用ブランディングの提案」として成立していました。しかし、読み比べてみると、驚くほど方向性が違う。施策の優劣ではありません。そもそも、何を問題と見なしているかが違うのです。
この違いの正体を考えていくと、「AIは合理的な答えをくれる」という私たちの思い込みそのものが揺らぎ始めます。
まず実験結果の核心部分からお伝えします。
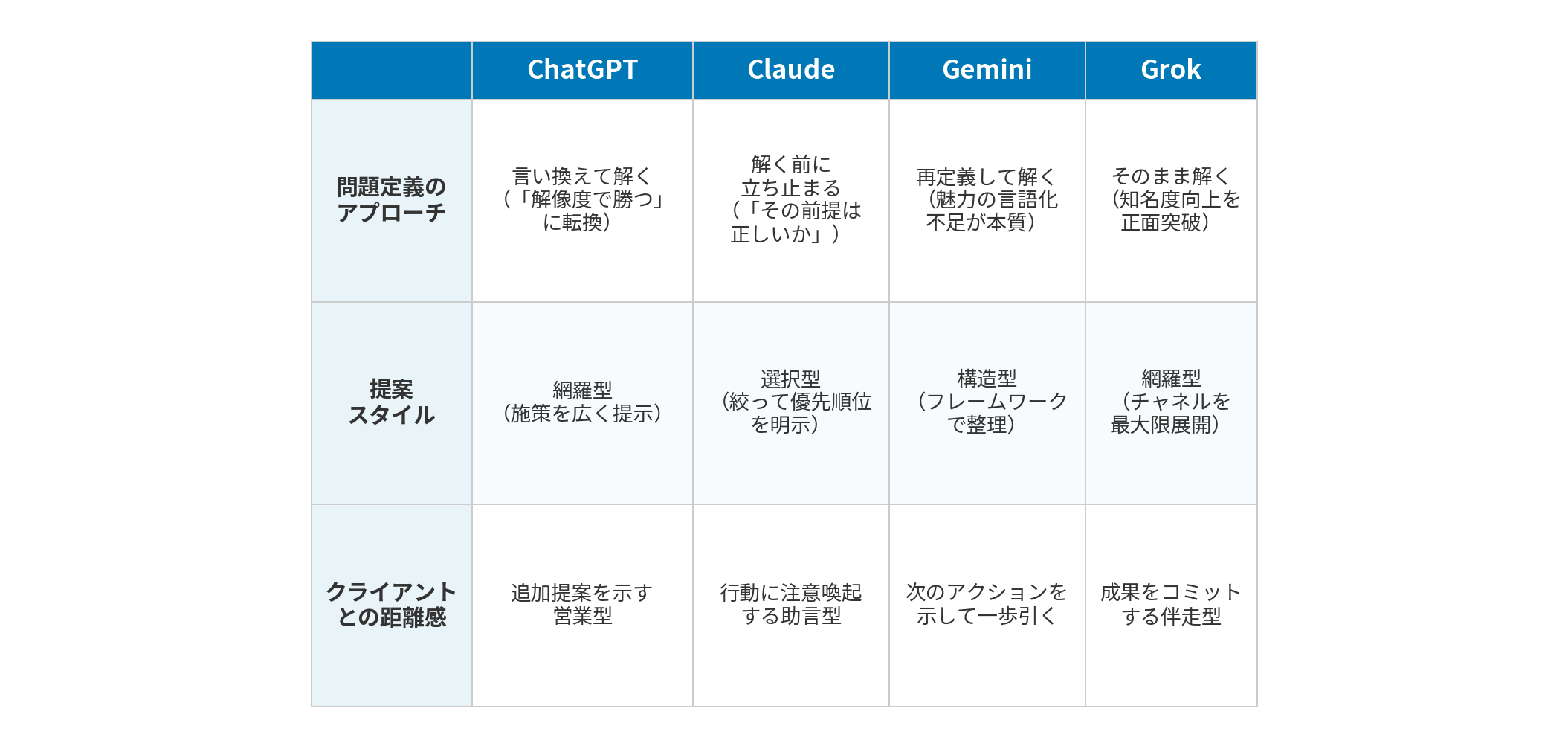
課題文には「知名度が低いことが最大のボトルネック」と明記しました。この一文に対する4つのLLMの反応が、最も構造的な違いを示しています。
ChatGPTは「知名度で勝つのではなく解像度で勝つ」と再定義しました。知名度が低いこと自体は問題として受け入れた上で、戦い方を変えるべきだという提案です。Grokは「知名度が低い」をほぼそのまま受け入れ、知名度を上げるための施策を網羅的に展開しました。SNS運用からYouTube Shorts、TikTok、connpassでの勉強会まで、あらゆるチャネルでの露出強化を提案しています。
一方、Geminiは冒頭で「エンジニア採用において一般的な知名度はさほど重要ではありません」と明確に否定し、本当の問題はEVP(従業員価値提案)が言語化されていないことだと診断し直しました。Claudeはさらに踏み込み、「知名度がボトルネックという分析は本当に正しいか」と問い返し、施策の前にまず内定辞退者の声を聞くべきだと主張しています。
整理すると、こうなります。Grokは与えられた問題をそのまま解く。ChatGPTは問題を言い換えて解く。Geminiは問題を再定義して解く。Claudeは問題を解く前に立ち止まる。
同じインプットを渡しているのに、4つのAIが見ている「問題」がそもそも違う。これは単なる回答のバリエーションではなく、もっと根深い構造の違いを示しているのではないかと考えます。
この違いは、どこから来るのでしょうか。
各LLMは、異なる企業が、異なる設計思想のもとで作っています。OpenAI(ChatGPT)はAGI——汎用人工知能の実現を掲げ、幅広い問題に対応できる汎用性を重視しています。Anthropic(Claude)はAIの安全性研究を中核に据え、慎重さや誠実さを設計原則としています。Google(Gemini)は検索エンジンで培った情報整理の技術を背景に持ち、構造的な分析に強みがあります。xAI(Grok)はXのデータへのアクセスを強みとし、リアルタイム性と率直さを志向しています。
さらに、訓練データという「文化的な土壌」の違いもあります。どのデータを、どのくらいの比率で学習したかによって、世界の捉え方の枠組み自体が変わってくる。これは、同じ「合理的な提案」でも、何に対して最適化されているかで中身がまったく異なることを意味しています。
ここで重要なのは、4つの回答のどれが「正解」かという問いには意味がないということです。
すでに課題が明確で実行フェーズにいる企業にとっては、ChatGPTやGrokの網羅的な施策リストのほうが実用的でしょう。逆に、そもそも何が問題かを整理したい段階にいる企業にとっては、GeminiやClaudeの「前提を疑う」アプローチのほうが価値がある。それぞれのAIが持つ「合理性の方向」が、異なる状況に対して異なる有効性を持っているだけです。
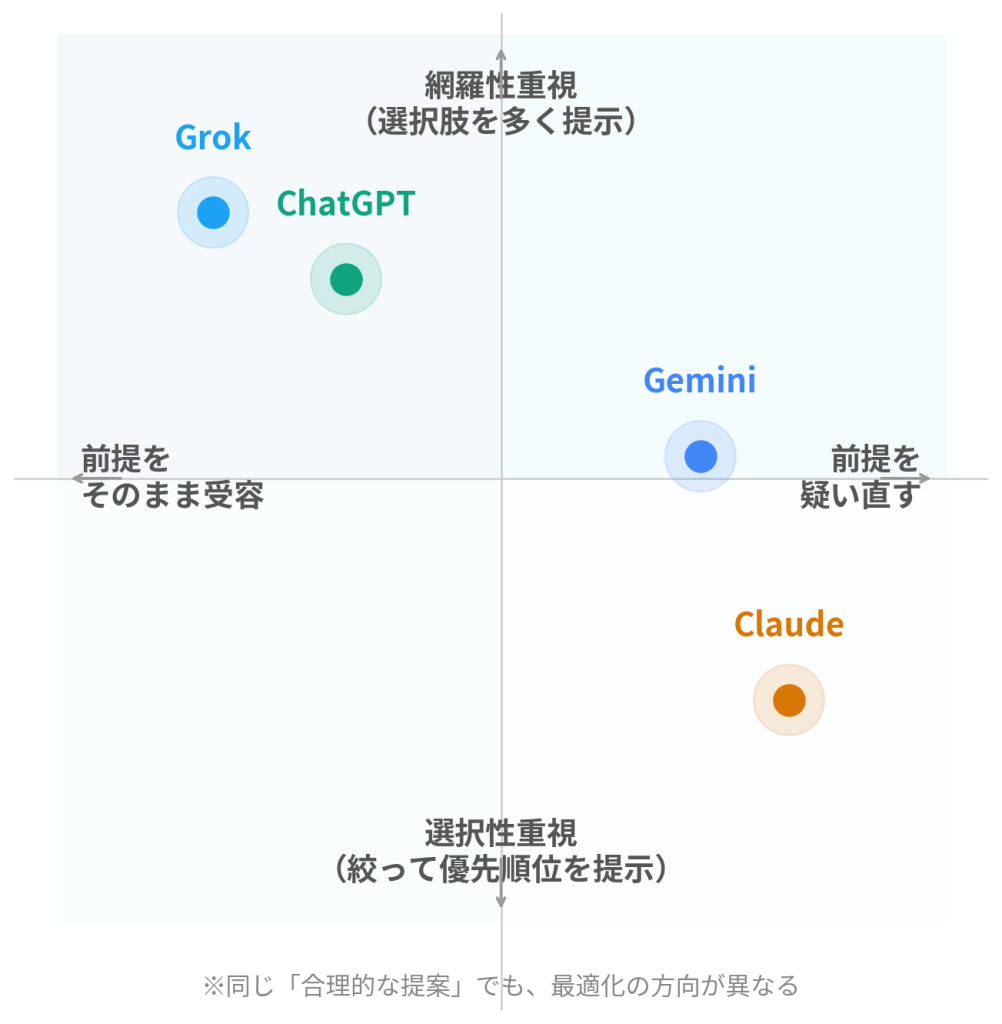
「AIは合理的だから正しい答えをくれる」という期待は、おそらくこの構造を見落としています。合理的であること自体は間違いないのですが、どの方向に合理的なのかが違う。速い・遅い、賢い・そうでないという一次元の性能比較では、この違いは捉えられません。
私は日常的にこの4つのLLMを使い分けていますが、以前からClaudeとGeminiに「好み」がありました。ChatGPTやGrokの回答は、悪くはないけどどこか「しっくりこない」と感じることが多かった。ただ、その理由をうまく言語化できずにいました。
今回の実験で、この好みの正体がはっきりしたように思います。私が好んでいたのは「前提を疑う」「いきなり答えに飛びつかない」というアプローチであり、それは私自身のコンサルタントとしての思考スタイルと合致していたのです。クライアントから「知名度が低いのが問題です」と言われたとき、「本当にそうですか?」と問い返すのが私の仕事のやり方だからです。
逆に、ChatGPTやGrokの「与えられた課題を全力で解く」「網羅的に選択肢を提示する」スタイルは、すでに問題が定義された後の実行フェーズでは極めて有効でしょう。どちらが優れているという話ではなく、どちらが自分の思考と共鳴するかの違いです。
ただし、ここにマーケターとして自覚すべきリスクがあると考えています。
自分と相性の良いAIばかりを使い続けると、自分の思考の偏りがAIによって増幅されていく。前提を疑うタイプの人間が、前提を疑うタイプのAIとだけ対話していれば、いつまでも前提の検討が終わらないかもしれない。実行力のある人間が、実行寄りのAIとだけ対話していれば、間違った方向に全速力で走り続けるかもしれない。いわば「確認バイアスのAI版」とでも呼べる現象です。
「自分はどのAIの”正しさ”に乗っているのか」。この問いを自覚的に持てるかどうかが、AIをツールとして使いこなすか、AIに思考を規定されるかの分岐点になるのではないでしょうか。
ここまでは「マーケターがAIを使う側」の話でした。しかし、この構造にはもう一段先があります。消費者自身がAIを使って意思決定をする時代が、すでに始まっているということです。
商品の比較検討をAIに任せる。旅行の計画をAIに相談する。転職先の選定にAIの意見を参考にする。こうした行動は、もはや一部のアーリーアダプターだけのものではありません。
このとき、同じ消費者が、使うAIによって異なる選択をする可能性がある。ChatGPTに相談した消費者は網羅的な比較をもとに「最も条件の良い選択肢」を選び、Claudeに相談した消費者は「そもそもその選び方でいいのか」を考え直して別の行動を取るかもしれません。
マーケティングの仮説モデル——ペルソナ設計やカスタマージャーニーは、暗黙に特定の「人間像」を前提としています。この人はこういう情報を集めて、こういう基準で比較して、こういうプロセスで購買に至る、と。従来、この前提の違いは「文化の違い」や「世代の違い」として議論されてきました。
しかし、AIが消費者の意思決定を媒介するようになると、新しい変数が加わります。「どのAIに媒介された消費者なのか」という変数です。同じ30代の日本人ビジネスパーソンであっても、日常的に使うAIが違えば、情報の集め方も判断の仕方も変わりうる。ペルソナの属性として「年齢」「職業」「価値観」だけでなく、「主に使うAI」を考慮する日が来るのは、それほど遠い話ではないかもしれません。
ただし、この議論には留保が必要です。現時点ではAIに最終的な購買判断を丸投げする消費者はまだ少数派でしょうし、AIの回答を参考にしつつも自分の判断で決める人がほとんどでしょう。AIが人間の意思決定を完全に代替するのではなく、意思決定のプロセスに影響を与える度合いが徐々に強まっていく、というのが現実的な見立てです。それでも、その「徐々に」が始まっていることは、マーケターとして意識しておく価値があると考えます。
マーケターがAIに施策を相談するとき、消費者がAIに商品を相談するとき、そこには必ず「どの合理性のフィルターを通しているか」という見えない前提がある。AIが賢くなればなるほど、その前提は見えにくくなっていきます。
私たちが選んでいるのは「ツール」ではなく、世界の切り取り方そのものなのかもしれません。